High throughput biomarker discovery technologies generate massive amounts of data, but
rapid discovery requires more than just analytical speed. That is why we’ve built an expert
data science team to interpret these large-scale datasets for actionable insight.
Sapient provides you with advanced biocomputational support for:
This allow us to identify key biomarkers of interest and map both their genotype and phenotype associations related to:
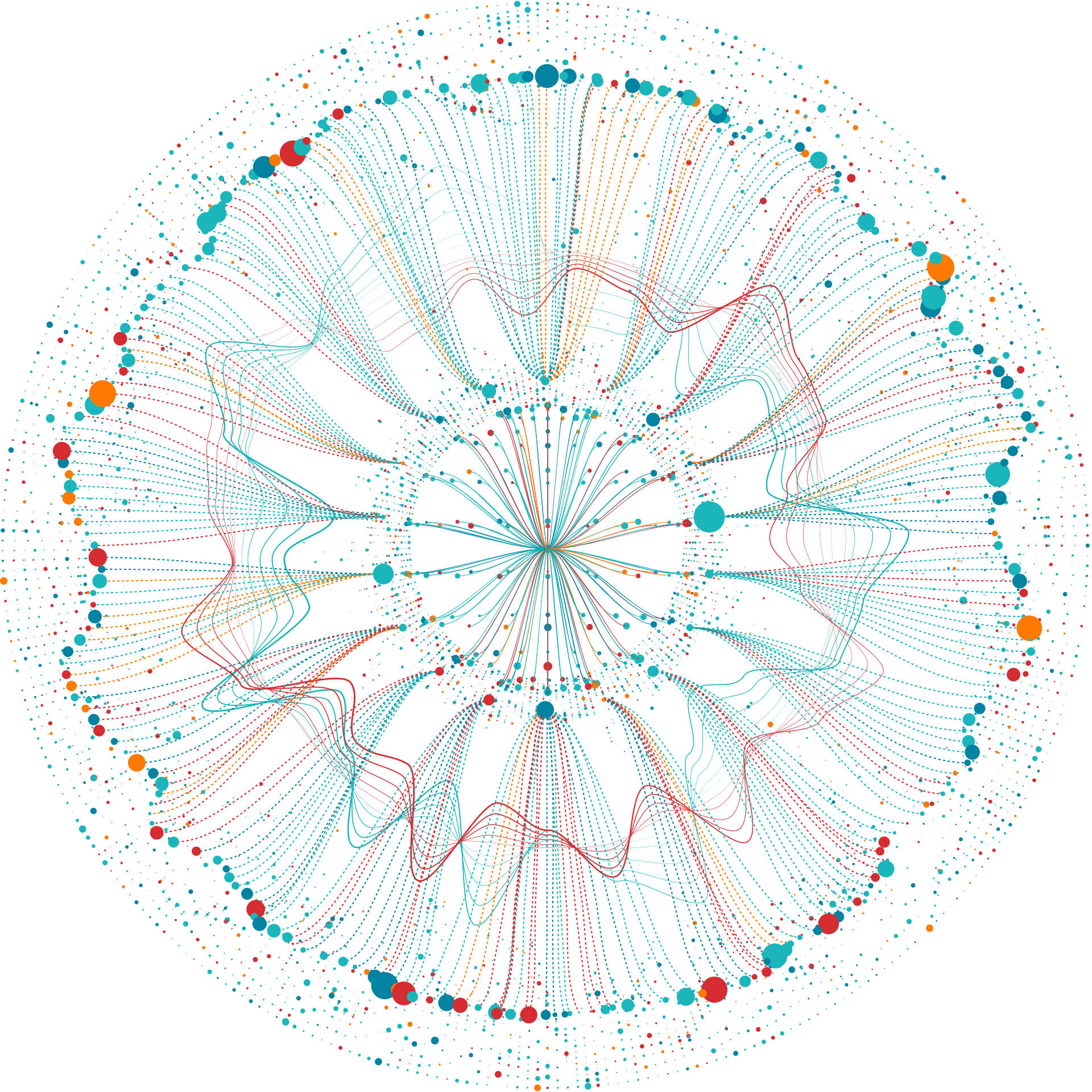
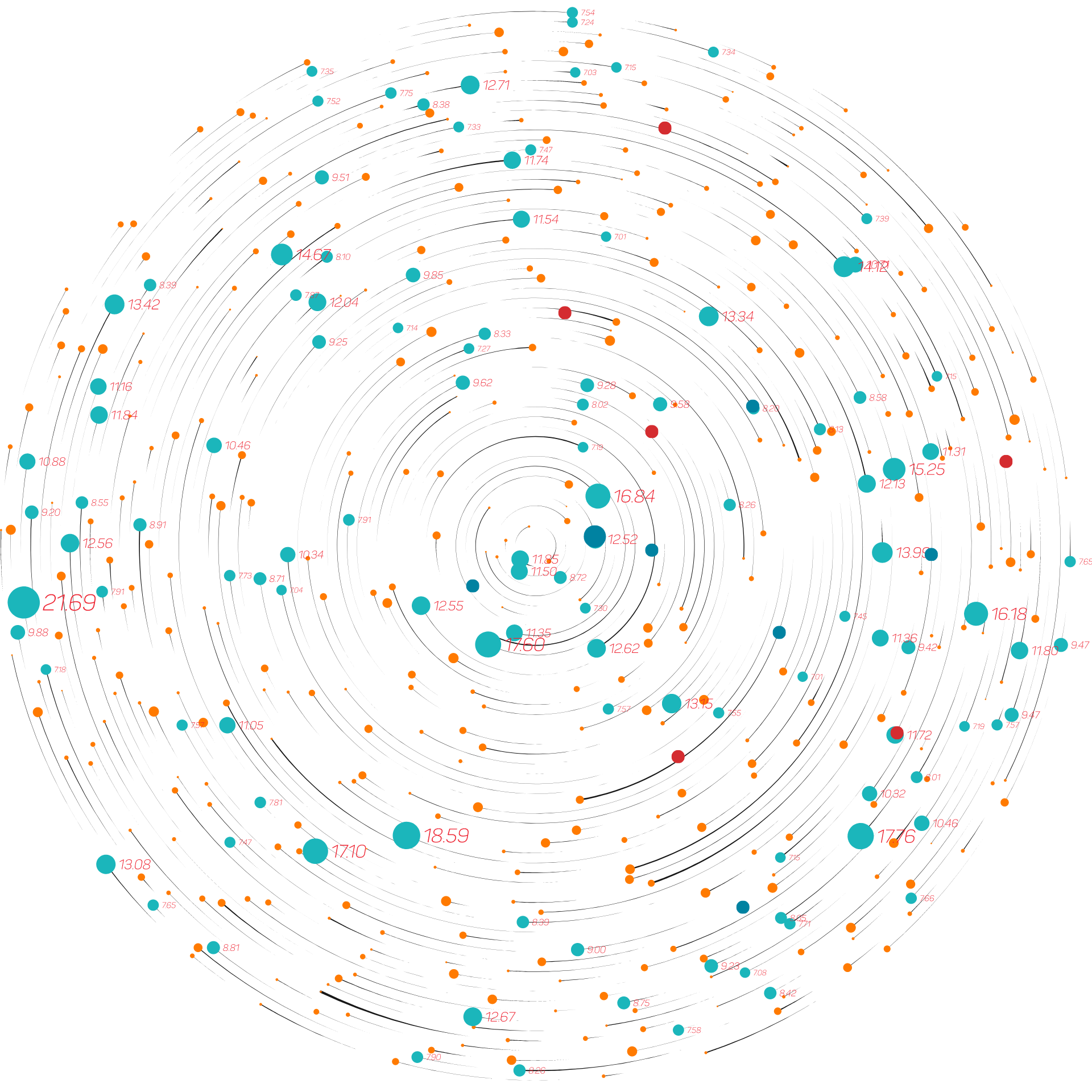
Sapient’s Human Biology Database is comprised of data from >100,000 biosamples already run on our mass spectrometry platform. The samples represent diverse individuals and disease areas, and are paired with longitudinal data including adjudicated clinical outcomes spanning 10-30 years.
The database allows us to:
We build our biocomputational approach around your context of use, working collaboratively with your team to define experiments that give you the data you need for the phase you’re in. This could include analysis of biomarkers that inform:
Identify therapeutic targets that may be involved in the pathogenesis of a specific disease.
Confirm a target’s role in disease process and/or the effects of pharmacological modulation of the target.
Demonstrate the drug reaches its intended target with measurable binding effect.
Evaluate the biological activity of a drug.
Identify genetic and/or environmental factors that predispose to disease and/or cause disease progression.
Monitor disease status, the occurrence of new disease effects, and/or change in disease severity.
Select patients according to disease-based or drug-based biomarker signatures.
Select patients most likely to respond to a treatment to increase study power while reducing study size.
Assess the presence or extent of toxicity related to an intervention or drug exposure.
Identify predictive biomarkers that identify suitable patients for a treatment.
"*" indicates required fields
10421 Wateridge Circle, Suite 100
San Diego, CA 92121
discover@sapient.bio
858.290.7010
© 2024 Sapient Bioanalytics, LLC. All rights reserved.
SAPIENT, the SAPIENT Logo, ACCELERATE HUMAN DISCOVERY, and SPECIFICITY AT SCALE are trademarks of Sapient Bioanalytics, LLC