Mapping Metabolic Changes for Diabetes Prediction with Machine Learning
Understanding the risk factors that give rise to human disease is essential to early detection and development of effective treatments for disease prevention. Human disease risk represents an interaction between underlying genetic predisposition, which is largely set from the moment of conception, and the varied and changing exposures that occur over an individual’s lifetime, including from diet, lifestyle, the environment, internal organs, and the microbiome.
The degree of risk that originates from genetic vs. non-genetic factors has been modeled using a variety of tools, including the study of monozygotic and dizygotic twins (Rappaport 2016). From these studies, it has been found that the majority of lifetime attributable disease risk is related to non-genetic causes, particularly for complex, heterogenous diseases such as diabetes.
Figure 1. Population attributable fractions for multiple disease phenotypes, including diabetes, estimated from studies of mono and dizygotic twins. Rappaport PLoS. 2016.
Figure 2 below represents an rLC-MS analysis of over 40,000 circulating small molecule factors in tens of thousands of individuals from many different studies collected from dozens of sites around the world. These individuals have diverse socioeconomic backgrounds, diets, and lifestyles, and have been followed for up to two decades years.
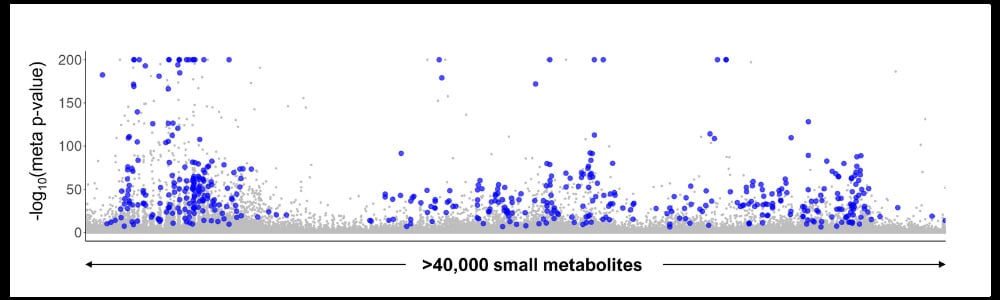
Figure 2. Across a study of tens of thousands of diverse individuals, we find hundreds of metabolites that associate with incident diabetes development >10 years in advance.
Through time-to-event analysis, we found hundreds of biomarkers present in ‘pre-disease’ states that predict the development of incident diabetes more than 10 years in advance. Each blue dot on the plot represents a small molecule that cross-validates across different studies and diverse populations, confirming the robust nature of the discovery and consistency in findings despite the heterogeneity of the underlying populations.
While it is now possible to generate large-scale small molecule biomarker data very rapidly, the ability to interpret that data for actionable insight and knowledge has not scaled at the same rate. Machine learning (ML) now enables the processing power required to unite voluminous, multi-dimensional data assets such as small molecule measures and genomics, and enable rapid, accurate classifier analysis to identify associations with incident disease development.
When we look long term at disease risk over a ten-year period, as shown in Figure 3, we find that ML-based classifiers using metabolic risk scores (MRS) have tremendous predictive power, clearly differentiating the top 25% of individuals at the highest risk of developing diabetes over a decade. It also allows us to understand how risk increases over time, and particularly how common risk factors such as obesity interact with MRS to influence disease risk.
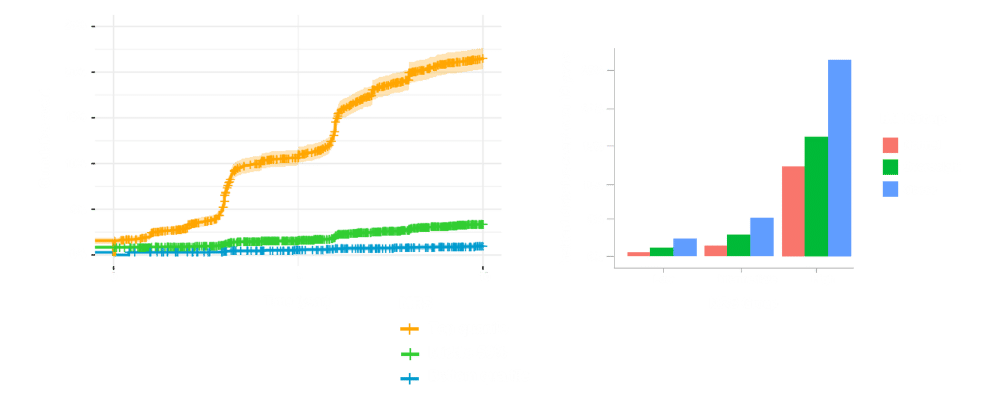
Figure 3. ML-based classification of long-term diabetes risk and impact of BMI on MRS to influence disease risk.